©2026 Chris McWain
Grabbing Stock Quotes
May 1, 2024 at 16:30
This will probably get me in trouble for sharing, but since less than ~700 of you read my site, it likely won’t matter much.
There are a few resources that elude my intermediate web-scraping skills, but one managed to get knocked off that list today. Finviz, as mentioned in my Digital Toolkit post, is a “free stock market visualization tool.” Their site is critical to have in your investment bookmarks because it provides an incredible amount of information. This scraping method is basic for anyone that is familiar, but I’ll take you along my journey of learning.
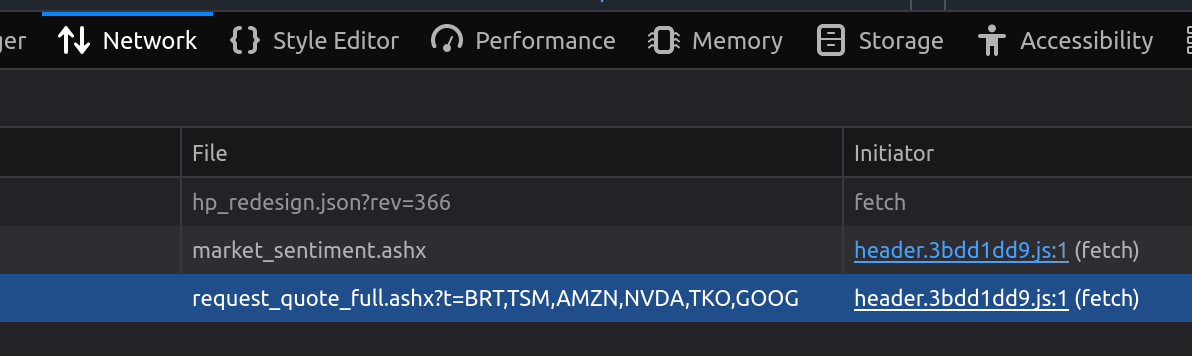
Inspecting the site’s network requests, one popped up that looked really straightforward. Bringing up their request URL in a browser will return a simple table of the tickers found in the URL-formatted string. You can add as many tickers as you want, as long as the stock is available (sorry, no DOGE-USD), and the URL stays formatted properly.
Note: %2C is URL speak for a comma.
https://finviz.com/request_quote_full.ashx?t=BRT%2CTSM%2CAMZN%2CNVDA%2CTKO%2CGOOG
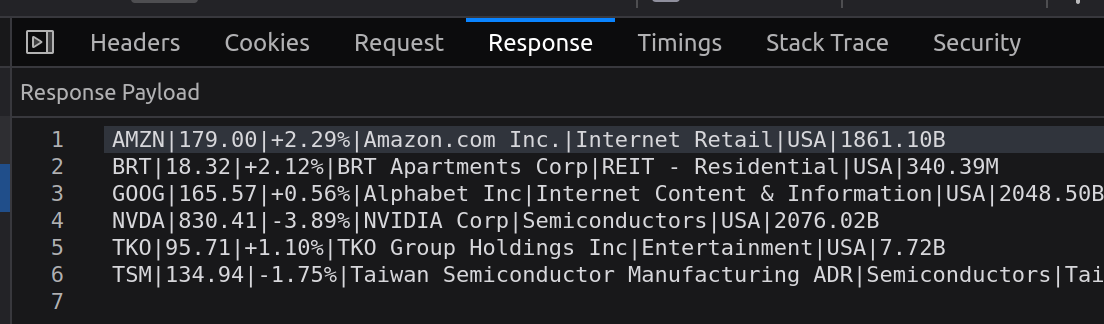
I wrote a quick Python scraper that used BeautifulSoup to grab elements from the <pre> tag, but it came up empty. Clearly, they have basic scraping blocked. I tried adding headers and user agents, but still nothing. Eventually, I switched over to Playwright and it worked with headless=false, but failed with headless=true. This told me the data is there, but they didn’t recognize my request as a valid browser. At the bottom of this post is the script after tweaking. The arguments passed into Chromium were just enough to grab what I needed and print to the terminal.
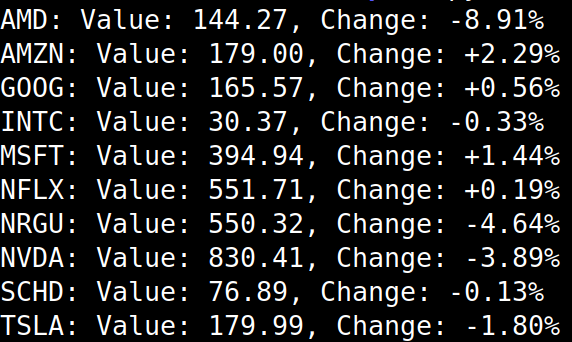
This won’t be used for anything critical as I don’t want to overwhelm their site, but it was an interesting learning experience for someone who needs as much experience as he can get his hands on.
stock_scraper.py
from playwright.sync_api import sync_playwright
def fetch_stock_data():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True, args=[
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-infobars',
'--window-size=1920,1080',
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
])
page = browser.new_page()
page.set_viewport_size({"width": 1920, "height": 1080})
url = "https://finviz.com/request_quote_full.ashx?t=GOOG%2CAMZN%2CNVDA%2CNFLX%2CSCHD%2CINTC%2CTSLA%2CAMD%2CMSFT%2CNRGU"
page.goto(url)
data = page.text_content('pre')
browser.close()
if data:
stock_info = {}
lines = data.splitlines()
for line in lines:
parts = line.split('|')
if len(parts) > 2:
stock_name = parts[0]
stock_value = parts[1]
stock_change = parts[2]
stock_info[stock_name] = f"Value: {stock_value}, Change: {stock_change}"
return stock_info
else:
print("No data found in <pre> tags")
return {}
stock_data = fetch_stock_data()
for stock, details in stock_data.items():
print(f"{stock}: {details}")
Questions or comments?